
티스토리 뷰
목차
"테크씬 - 핵심 요약 후 시작합니다."
- Elastic MapReduce(EMR)는 Amazon Web Services(AWS)의 클라우드 기반 빅 데이터 처리 서비스로, 확장 가능한 클러스터, Hadoop 호환성, AWS 통합을 제공함
- EMR의 주요 경쟁 서비스로는 Apache Hadoop, Google Cloud Dataproc, Microsoft Azure HDInsight, Cloudera, Hortonworks 등이 있으며, 각기 고유한 기능과 장점을 가지고 있음
- 조직은 비즈니스 요구 사항과 목표를 결정하고, 데이터 소스 및 스토리지 옵션을 평가하며, 각 조직의 요구사항에 따라 최적의 빅데이터 처리 솔루션을 선택해야 함
- 효율적인 빅데이터 처리를 위해 클러스터 규모와 구성을 최적화하고 빅데이터 처리 서비스의 성능, 가용성, 보안을 모니터링/관리하는 것은 필수적임
안녕하세요, 테크씬입니다. 오늘날의 디지털 시대에 기업과 조직은 끊임없이 대량의 데이터를 생성하고 있죠. 빅데이터 처리는 조직 운영에서 매우 중요한 측면이 되었습니다. 이러한 수요를 충족하기 위해 Elastic MapReduce(EMR), Apache Hadoop, Google Cloud Dataproc, Microsoft Azure HDInsight, Cloudera 등 다양한 빅 데이터 처리 서비스가 등장했습니다. 이 글에서는 인기 있는 솔루션인 EMR과 그 대안(or 경쟁제품)들을 비교하고 기업에서 사용하기 위한 가이드를 제공합니다.
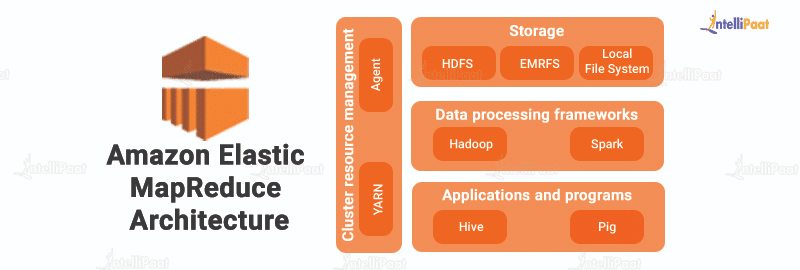
Elastic MapReduce(EMR)
EMR은 Amazon Web Services(AWS)에서 제공하는 클라우드 기반 빅 데이터 처리 서비스입니다. 다음은 몇 가지 주요 기능, 장점 및 단점입니다:
주요 기능
- 확장 가능한 클러스터: EMR은 Amazon Elastic Compute Cloud(EC2) 인스턴스 클러스터를 생성하고 확장할 수 있으므로 대량의 데이터를 쉽게 처리할 수 있습니다.
- Hadoop 기반: EMR은 Apache Hadoop을 기반으로 하므로 Hadoop 에코시스템과 호환됩니다.
- AWS와 통합: EMR은 S3 및 Redshift와 같은 다른 AWS 서비스와 통합할 수 있어 데이터를 쉽게 저장, 처리 및 분석할 수 있습니다.
장점
- 비용 효율적입니다: EMR의 종량제 가격 모델은 모든 규모의 조직에서 비용 효율적으로 사용할 수 있습니다.
- 확장 가능: 확장성: EMR의 확장 가능한 클러스터는 대량의 데이터와 처리 작업을 처리할 수 있습니다.
- 간편한 사용: EMR의 웹 기반 콘솔과 API를 사용하면 빅 데이터 처리 작업을 쉽게 설정, 구성 및 관리할 수 있습니다.
단점
- 가파른 학습 곡선: EMR은 복잡할 수 있으며 빅 데이터 처리 및 Hadoop에 대한 고급 지식이 필요합니다.
- 제한된 사용자 지정: EMR은 다른 빅 데이터 처리 서비스만큼 사용자 지정이 쉽지 않을 수 있습니다.
EMR의 경쟁 제품 및 대체재
EMR의 대안 조직에서 고려할 수 있는 EMR의 대안에는 여러 가지가 있습니다. 다음은 그 중 일부입니다:
1. Apache Hadoop:
- Apache Hadoop은 IT 업계에서 널리 사용되는 오픈 소스 빅 데이터 처리 프레임워크입니다. 분산 스토리지, 배치 처리, 실시간 처리와 같은 기능을 제공합니다.
- Elastic MapReduce(EMR)와 비교할 때, Hadoop은 더 구체적인 사용자 정의와 높은 유연성을 제공하므로 고급 빅 데이터 처리 요구가 있는 조직에 적합한 선택이 될 수 있죠.
- 그러나 Hadoop은 복잡합니다. 즉, 보다 간소화된 사용자 환경과 다른 AWS 솔루션들을 통합하여 사용하고자 하는 기업/조직에게는 EMR이 보다 좋은 선택이기에 깊이 있게 고민해야 합니다.
2. Google Cloud Dataproc:
- Google Cloud Dataproc은 완전 관리형 빅데이터 처리 서비스로 Hadoop, Spark, Hive 클러스터를 제공합니다. BigQuery 및 Cloud Storage와 같은 다른 Google Cloud 서비스와 쉽게 통합할 수 있습니다.
- Elastic MapReduce(EMR)와 비교할 때, Google Cloud Dataproc은 클라우드 스토리지와의 손쉬운 통합, 여러 빅 데이터 처리 프레임워크 지원, 확장성 등 유사한 기능을 갖추고 있습니다.
- 그러나 Google Cloud Dataproc은 가격 및 클러스터 관리에서 더 많은 유연성을 제공할 수 있으므로 비용 효율성과 빅 데이터 처리 서비스에 대한 제어를 우선시하는 조직에게 인기 있는 선택이 될 수 있습니다.
3. Microsoft Azure HDInsight:
- Microsoft Azure HDInsight는 완전 관리형 빅 데이터 처리 서비스로 Hadoop, Spark 및 Hive 클러스터를 제공합니다. Azure Blob Storage 및 Azure Data Lake Storage와 같은 다른 Microsoft Azure 서비스와 쉽게 통합할 수 있습니다.
- EMR과 비교할 때, HDInsight는 Microsoft Azure 서비스와의 보다 포괄적인 통합에서 유리하죠. Excel 및 Power BI와 같은 Microsoft 도구에 대한 더 나은 지원을 제공합니다. 즉, Amazon이 더 잘 맞는 유저가 있고 MS가 더 잘 맞는 유저가 있으니 통합적인 관점에서 취향(?)을 제대로 리뷰해 보시길 추천드려요.
4. Cloudera:
- Cloudera는 데이터 관리, 분석 및 머신 러닝을 위한 Hadoop 기반 솔루션을 제공하는 빅 데이터 처리 플랫폼입니다. 온프레미스(사내에 직접 인프라 구성) 및 클라우드 기반 솔루션을 모두 제공합니다.
- EMR과 비교했을 때, Cloudera는 더 다양한 사용자 지정 옵션을 보유하며, 고급 분석 기능, 더 강력한 컴플라이언스 기능을 제공하죠. 그러나, 유연성은 높은 만큼 설정/유지 관리에 더 많은 전문 지식과 리소스가 필요하다는 점을 기억하셔야 해요^^;
5. Hortonworks
- Hortonworks는 데이터 관리, 분석 및 머신 러닝을 위한 Apache Hadoop 기반 솔루션을 제공하는 빅 데이터 처리 플랫폼입니다. 이는 오픈 소스 플랫폼이에요. Hortonworks는 Hadoop 기반 데이터 관리, 분석 및 기계 학습을 포함한 포괄적인 빅 데이터 처리 솔루션 제품군을 제공합니다.
- EMR과 비교했을 때 Hortonworks는 조직의 특정 요구사항에 맞게 빅데이터 처리 환경을 조정할 수 있는 보다 맞춤화되고 유연한 솔루션을 제공합니다. (그래서 더 복잡...해요...)
기업/조직 적용을 위한 추천 Steps
실제 기업에서 빅데이터 처리 서비스를 사용하려면 조직은 다음 가이드를 고려해야 합니다.
1. 비즈니스 요구 사항과 목표 결정:
조직은 해결하고자 하는 비즈니스 문제를 파악하고 빅 데이터 처리를 통해 달성하고자 하는 목표를 사전에 결정해야 합니다.
예시: 넷플릭스는 빅데이터 처리를 통해 콘텐츠 추천을 개인화하고 고객 만족도를 개선합니다.
2. 데이터 소스 및 저장 옵션 평가:
조직은 처리/저장해야 하는 데이터의 유형, 용량, 품질을 평가해야 합니다. 또한 다양한 데이터 저장 옵션의 보안, 접근성, 비용도 고려해야 하죠.
예시: Uber는 빅 데이터 처리를 통해 차량 호출 데이터를 분석하고 운영을 최적화합니다.
3. 최적의 빅데이터 처리 솔루션 선택:
조직은 시중에 다양하게 존재하는 빅데이터 처리 솔루션(or 서비스)의 기능, 가격, 호환성을 평가하여 우리 조직의 요구 사항과 가용한 예산에 가장 적합한 서비스를 선택해야 합니다.
예시: 에어비앤비는 대규모 데이터셋을 처리하고 검색 순위 알고리즘을 개선하기 위해, 구글 클라우드 Dataproc을 사용합니다.
4. 클러스터 크기와 구성 최적화:
조직은 빅데이터 처리 요구 사항과 데이터 양에 따라 적절한 클러스터 크기와 구성을 결정해야 합니다. 또한 처리 속도, 비용, 리소스 사용률과 같은 요소도 고려해야 하죠.
예시: Walmart는 Cloudera를 사용해 방대한 데이터 세트를 처리하고 실시간 인사이트를 생성하여 재고 및 가격 책정 전략을 최적화합니다.
5. 빅데이터 처리 서비스 모니터링/관리:
조직은 빅데이터 처리 서비스의 성능, 가용성, 보안을 지속적으로 모니터링해야 합니다. 최초에 인프라를 구성하고 시스템을 개발하는 것으로 끝이 아니죠. 빅데이터 처리 요구 사항을 충족하고 업계 규정을 준수하는지 계속하여 확인해야 합니다.
예시: 트위터는 방대한 양의 사용자 생성 콘텐츠를 처리하고 사용자 참여 수준과 고객 반응을 모니터링하기 위해 Apache Hadoop을 사용합니다.
6. 빅데이터 처리 서비스 보안성:
조직은 빅데이터 처리 서비스를 사이버 위협으로부터 보호하고 데이터 개인정보 보호 및 규정 준수를 보장하기 위해 보안 조치를 구현해야 합니다.
예시: Capital One은 Microsoft Azure HDInsight를 사용하여 재무 데이터를 처리하고 액세스 제어 및 암호화와 같은 보안 조치를 구현하여 중요한 정보를 보호합니다.
정리하며...
결론적으로, 기업과 조직에서의 빅 데이터 처리는 운영의 필수적인 측면으로 자리하였습니다. Elastic MapReduce(EMR)는 Amazon Web Services(AWS)에서 제공하는 인기 있는 빅데이터 처리 서비스이지만, Apache Hadoop, Google Cloud Dataproc, Microsoft Azure HDInsight, Cloudera, Hortonworks와 같은 여러 가지 대안도 존재하죠.
실제 기업에서 빅데이터 처리 서비스를 사용하려면 조직은 1) 비즈니스 요구 사항 및 목표 설정, 2) 데이터 소스 및 스토리지 옵션 평가, 3) 적합한 빅데이터 처리 솔루션 도입, 4) 클러스터 크기 및 구성 최적화, 5) 서비스 모니터링 및 관리, 6) 서비스 보안성과 같은 중점 사안을 체크해야 합니다.
이러한 체크 포인트를 제대로 확인하고, 빅데이터 처리를 구현함으로써 인사이트를 얻고, 운영을 개선하며, 마침내 비즈니스 목표를 달성할 수 있을 겁니다. 여러분의 조직은 어떤 솔루션을 사용하시나요? 혹은 어떤 솔루션을 택하고자 하시나요? 숙고하고 재고할 중요한 부분입니다^^. 오늘도 테크씬이었습니다.
[관련 포스팅]
2023.01.31 - [데이터] - 빅데이터 처리: Apache Spark로 혁신에 날개를 달다.
빅데이터 처리: Apache Spark로 혁신에 날개를 달다.
Big Data 처리는 많은 글로벌 기업 운영에서 핵심점인 요소로 대두했습니다. 그러나 전통적인 기술을 활용해서 대규모 데이터를 운영하는 경우도 사실 비일비재한 현실입니다.. 오늘은 Apache Spark
techscene.tistory.com
2023.02.12 - [데이터] - 쿠버네티스 및 EKS : 유연한 클라우드 컴퓨팅 세계
쿠버네티스 및 EKS : 유연한 클라우드 컴퓨팅 세계
"테크씬 - 핵심 요약 후 시작합니다." Kubernetes는 컨테이너화된(Containerized) 애플리케이션의 배포/확장 및 관리를 자동화하는 오픈 소스 플랫폼 (별명은 K8s랍니다. 너무 길어서 이렇게 쓰는 것 같습
techscene.tistory.com
'데이터' 카테고리의 다른 글
| CDO vs CIO : 데이터와 IT의 핵심 리더들 (0) | 2023.05.07 |
|---|---|
| 에어플로우의 놀라운 기능: Apache Airflow로 데이터 파이프라인 강화 (1) | 2023.04.05 |
| 팔란티어 경쟁사 비교: 데이터 통합 및 분석, 그리고 UX (0) | 2023.03.11 |
| 클라우드 전쟁 : AWS, GCP, Azure (0) | 2023.02.23 |
| Snowflake : 클라우드 기반 혁신적 데이터 웨어하우징 (0) | 2023.02.14 |