
티스토리 뷰
목차
안녕하세요, 테크씬입니다! 오늘의 포스팅에서는 최근 큰 관심을 끌고 있는 ChatGPT의 근간, 즉 LLM (Large Language Models)과 그 세부 조정 방법인 Fine-Tuning에 대해 깊이 있게 다룰 예정입니다. 기술에 대한 일반적인 이해가 부족한 분들을 대상으로 이 글을 작성하였으니 비전공, 비전문가라도 걱정 안 하셔도 좋습니다.^^. 목적은 LLM과 Fine-Tuning의 필요성과 그 활용 사례를 통해 여러분에게 새로운 지식과 통찰을 제공하는 것입니다. 지금 한번 같이 살펴보시죠.

관련된 인기 글 추천
1. LLM과 Fine-Tuning?
LLM이란 무엇인가?
Large Language Model(LLM)은 인공 지능(AI)의 한 분류로, 신경망 기술을 활용하여 인간의 언어를 처리하고 이해하는 알고리즘을 의미합니다. LLM은 대규모 데이터셋을 기반으로 학습되며, 단어의 문맥을 고려하여 다음 단어의 예측을 개선하는 능력을 갖고 있습니다. 이 능력은 LLM이 언어를 이해하고 창의성을 발휘할 수 있는 핵심 요소입니다.
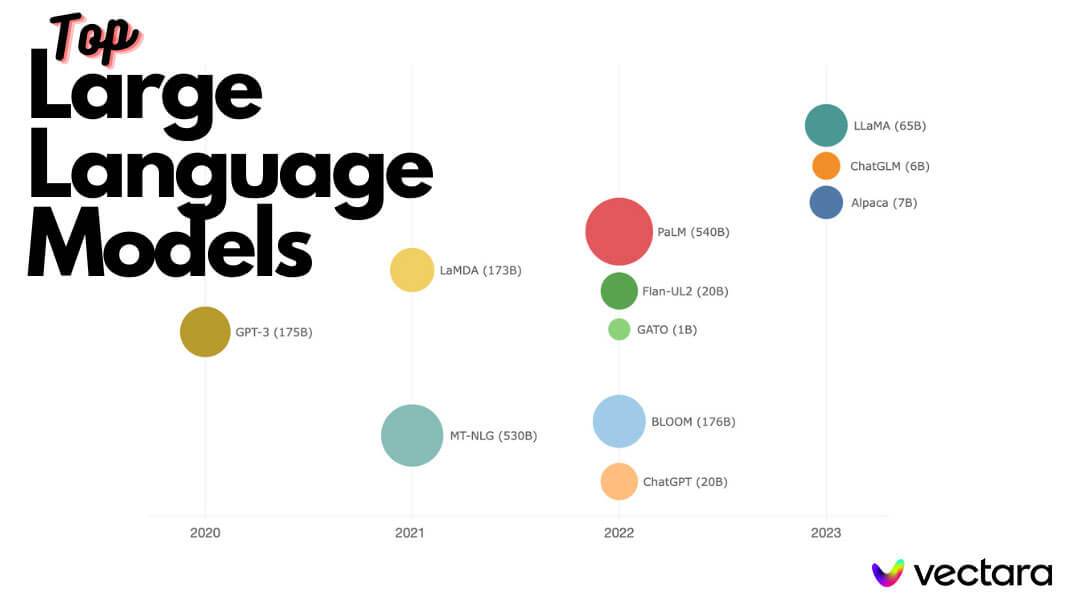
LLM은 다양한 자연어 처리(NLP) 작업을 수행할 수 있는 딥 러닝 알고리즘입니다. LLM은 transformer 모델을 활용하여 대규모 데이터셋을 학습하는 데 사용됩니다. 이러한 모델은 텍스트를 인식하고 번역, 예측 또는 생성하는 데 사용됩니다. 즉, LLM은 언어에 대한 이해를 기반으로 다양한 언어 작업을 수행할 수 있는 강력한 도구입니다.
LLM은 일반적으로 자연어 처리, 추천 시스템, 데이터 분석 등 다양한 분야에서 활용됩니다. 예를 들어, 언어 번역, 감정 분석, 챗봇과의 대화 등 많은 언어 작업을 수행할 수 있으며, 의료 분야, 소프트웨어 개발 및 다른 다양한 분야에서 LLM의 활용 사례를 발견할 수 있습니다.
LLM의 기본 구조는 transformer라는 신경망으로 구성되며, 인코더와 디코더로 이루어져 있습니다. 인코더와 디코더는 텍스트 시퀀스에서 의미를 추출하고 단어와 구절 사이의 관계를 이해하는 self-attention 기능을 갖고 있습니다. 이러한 기능을 통해 LLM은 놀라운 문장 생성 능력과 언어 이해 능력을 보여줍니다.
LLM의 일반적인 활용 분야
LLM은 다양한 분야에서 활용되고 있습니다. 자연어 처리(NLP), 기계 번역, 대화형 에이전트, 텍스트 분류 등 다양한 응용 분야에서 그 능력을 발휘하고 있습니다. 최근에는 메타러닝, 다중 작업 학습, 신뢰할 수 있는 AI 등의 연구 분야에서도 활용되고 있습니다.
특히, LLM은 기존의 작은 모델이 처리하기 어려웠던 복잡한 문제를 해결하는 데 효과적입니다. 예를 들어, GPT-3와 같은 모델은 문맥을 더 잘 이해하고, 다양한 작업에서 좋은 성능을 보이고 있습니다.
Fine-Tuning의 필요성 강조
Fine-Tuning은 LLM을 특정 작업이나 도메인에 맞게 조정하는 과정입니다. 예를 들어, 의료 분야의 텍스트 분석을 수행하려면 일반적인 언어 모델로는 부족할 수 있습니다. 이때 Fine-Tuning을 통해 모델을 해당 분야에 맞게 최적화할 수 있습니다.
더 나아가, Fine-Tuning은 다음과 같은 장점이 있습니다:
- 일반 모델을 특정 작업에 맞게 빠르게 적용할 수 있습니다.
- 데이터가 부족한 경우에도 미리 학습된 모델을 활용하여 높은 성능을 얻을 수 있습니다.
- 작업 특화 모델을 새롭게 학습하는 것보다 계산 비용이 훨씬 절약됩니다.
챗GPT에는 Fine-Tuning이?

챗GPT는 다양한 분야에서 활용되고 있는 대표적인 대화형 언어 모델입니다. 이 글에서는 챗GPT를 다양한 업계나 응용 프로그램에 맞게 Fine-Tuning한 실제 사례를 중심으로 알아보겠습니다.
고객 서비스 분야의 적용
챗GPT는 고객 서비스 분야에서 특히 두각을 나타내고 있습니다. Fine-Tuning을 통해 특정 업계의 용어와 대화 스타일에 맞게 훈련된 챗GPT는, 고객 질문에 대한 정확하고 신속한 응답이 가능합니다.
의료 분야의 적용
의료 분야에서는 챗GPT가 의료 상담, 증상 분석 등에 활용되고 있습니다. Fine-Tuning을 통해 의료 전문 용어와 질문 패턴을 학습한 챗GPT는 의료 서비스를 효율적으로 지원합니다.
교육 분야의 적용
교육 분야에서는 챗GPT를 활용한 가상의 교사나 튜터 시스템이 개발되고 있습니다. Fine-Tuning을 통해 교육과 관련된 다양한 주제와 질문 패턴을 학습한 모델은 학생들에게 개인화된 교육 경험을 제공합니다.
Fine-Tuning을 통해 챗GPT는 다양한 분야와 상황에 유연하게 적용될 수 있습니다. 이러한 적용 사례를 통해 챗GPT의 다양성과 유용성을 확인할 수 있습니다.
2. Fine-Tuning의 기본 원칙
Fine-Tuning은 이미 학습된 언어 모델(Large Language Model, 이하 LLM)을 특정 작업이나 도메인에 맞게 추가 학습시키는 과정입니다. 이를 통해 모델은 특정 작업에 대한 성능을 크게 향상할 수 있습니다. 이번 섹션에서는 Fine-Tuning의 기본 원칙을 구체적으로 다루어 보겠습니다.
원칙 1: 목적을 명확하게 설정하기
모델을 Fine-Tuning하기 전에, 목표를 명확하게 설정하는 것이 중요합니다. 목표 설정은 무엇을 위해 모델을 사용할 것인지, 어떤 문제를 해결하려고 하는지에 대한 지침을 제공합니다. 감정 분석, 문장 생성, 질문 응답 등 다양한 작업이 있을 수 있습니다.
예를 들어, 고객 서비스를 자동화하기 위한 챗봇을 개발한다면, 문제 해결 능력, 인간처럼 자연스러운 대화 능력 등을 중점적으로 고려해야 할 것입니다.
원칙 2: 적절한 데이터 선정
학습 데이터의 선정은 Fine-Tuning의 성공을 크게 좌우합니다. 데이터는 작업의 목적과 밀접하게 연관되어 있어야 하며, 충분한 양과 다양성을 가지고 있어야 합니다.
데이터가 너무 편향되어 있다면, 모델도 편향된 결과를 출력할 가능성이 높습니다. 따라서 다양한 시나리오와 케이스를 고려하여 데이터를 수집해야 합니다.
원칙 3: 전처리와 후처리
데이터 전처리는 모델 학습에 앞서 이루어지는 중요한 단계입니다. 이 단계에서는 노이즈를 제거하고, 데이터를 모델이 이해할 수 있는 형식으로 변환합니다. 예를 들어, 텍스트 데이터의 경우 특수 문자 제거, 대소문자 통일, 불용어 제거 등이 이에 해당합니다.
또한, 모델이 예측한 결과를 실제 응용 분야에 적용하기 전에 후처리 과정이 필요할 수 있습니다. 예를 들어, 모델이 생성한 텍스트에 문법적 오류나 논리적 모순이 있다면 이를 수정해야 합니다.
원칙 4: 모델 아키텍처와 하이퍼파라미터
모델의 아키텍처와 하이퍼파라미터 선택은 성능에 큰 영향을 미칩니다. 기존에 학습된 모델의 구조를 잘 이해하고, 필요한 경우 하이퍼파라미터를 조정하는 것이 중요합니다.
예를 들어, 학습률(learning rate), 배치 크기(batch size), 에포크(epoch) 수 등은 학습 과정에서 조절할 수 있는 하이퍼파라미터입니다. 이 값들을 적절히 설정하면 모델의 성능을 향상할 수 있습니다.
원칙 5: 평가 메트릭스 활용
학습이 완료된 모델의 성능을 정확하게 평가하기 위해 다양한 메트릭스를 활용할 수 있습니다. 정확도(accuracy), 정밀도(precision), 재현율(recall), F1 스코어 등 다양한 평가 지표가 있습니다.
이러한 지표들은 모델이 실제로 얼마나 잘 작동하는지, 어떤 부분을 개선해야 하는지에 대한 힌트를 제공합니다.
원칙 6: 지속적인 모니터링과 업데이트
Fine-Tuning을 통해 모델을 개선한 후에도, 지속적인 모니터링과 업데이트가 필요합니다. 사용자의 피드백, 새로운 데이터, 변경된 목표 등을 반영하여 모델을 지속적으로 개선해야 합니다.
예를 들어, 고객 서비스 챗봇의 경우 시간이 지남에 따라 고객의 질문 유형이 변할 수 있습니다. 이러한 변화에 빠르게 대응하기 위해 지속적인 모니터링이 필요합니다.
원칙 7: 실험과 검증
모델을 Fine-Tuning할 때는 다양한 설정과 하이퍼파라미터로 실험을 해야 합니다. 이렇게 하면 어떤 설정이 최적의 성능을 내는지 알 수 있습니다. 실험 결과는 꼼꼼하게 문서화하여 나중에 참고할 수 있게 해야 합니다.
예를 들어, 학습률을 다르게 설정하여 여러 번 실험을 실행하고, 그 결과를 비교 분석할 수 있습니다.
원칙 8: 윤리적 고려사항
모델을 Fine-Tuning하고 사용할 때는 윤리적인 측면도 고려해야 합니다. 데이터의 프라이버시, 모델이 생성할 수 있는 편향된 정보 등을 신중하게 다루어야 합니다.
데이터 수집 단계에서부터 윤리적인 문제가 발생할 수 있으므로, 이러한 문제를 미리 예방하는 방안을 마련해야 합니다.
3. Fine-Tuning의 주요 고려사항
Fine-Tuning 과정에서는 성공적인 결과를 얻기 위해 몇 가지 핵심 요소를 고려해야 합니다. 이 섹션에서는 그러한 요소들에 대해 깊이 있게 다룹니다.
1 데이터 셋의 품질과 양
- 데이터 셋의 품질: 모델의 성능은 주로 사용된 데이터의 품질에 의존합니다. 이상치, 노이즈, 불균형 클래스 등이 포함되지 않아야 합니다.
- Data Augmentation: 데이터 증가 방법도 고려할 수 있습니다. 이미지 데이터의 경우, 회전, 반전 등의 방법이 있습니다.
- 데이터 셋의 양: 대량의 데이터는 일반적으로 모델 성능을 향상하지만, 오버피팅의 위험이 있습니다.
- Data Sampling: 데이터가 많은 경우, 효율적인 샘플링 전략을 고려할 수 있습니다.
2 하이퍼파라미터 설정
- Learning Rate: 학습률은 모델 훈련의 가장 중요한 하이퍼파라미터 중 하나입니다.
- Learning Rate Scheduler: 학습률을 동적으로 조정하는 방법도 있습니다.
3 모델 아키텍처
- 레이어의 수와 유닛: 더 복잡한 문제를 해결하기 위해선 더 많은 레이어와 유닛이 필요할 수 있습니다.
- Transfer Learning: 미리 훈련된 모델을 사용하여 훈련 시간과 비용을 줄일 수 있습니다.
4 Regularization Techniques
- Dropout: 오버피팅을 방지하기 위해 학습 중 일부 뉴런을 무작위로 비활성화합니다.
- Dropout Rate: 어느 비율의 뉴런을 비활성화할지 결정합니다.
- Weight Decay: 가중치 감소는 오버피팅을 방지하기 위해 가중치의 크기를 제한합니다.
- L1 and L2 Regularization: 가중치에 페널티를 부여하는 다른 방법입니다.
5 Evaluation Metrics
- Accuracy, Precision, and Recall: 모델 성능을 평가할 때 다양한 지표를 사용해야합니다.
- F1 Score: 정밀도와 재현율의 조화 평균을 나타냅니다.
6 환경과 자원
- 계산 자원: GPU나 TPU 등의 하드웨어 가속기는 훈련 속도를 크게 향상할 수 있습니다.
- Cloud vs On-Premises: 클라우드와 온프레미스 환경의 장단점을 비교해 보세요.
- 배포 환경: 모델을 실제로 배포할 때는 성능, 비용, 확장성 등을 고려해야 합니다.
- Auto-scaling: 트래픽에 따라 자동으로 리소스를 조정하는 기능
4. 모델 검증과 테스트
- Cross-Validation: 모델의 일반화 성능을 평가하기 위해 교차 검증을 사용할 수 있습니다. K-Fold 교차 검증은 이러한 방법 중 하나입니다.
- Stratified K-Fold: 클래스 불균형 문제를 해결하기 위해 계층화된 K-Fold 방법을 사용할 수 있습니다.
- A/B Testing: 배포 후에도 A/B 테스트를 통해 모델 성능을 지속적으로 모니터링해야 합니다.
- Multi-Armed Bandit: 여러 모델을 동시에 테스트하고 성능이 좋은 모델에 자원을 더 할당하는 전략입니다.
진행 상황 모니터링
- TensorBoard나 MLflow 같은 도구: 훈련 중의 모델 성능을 실시간으로 모니터링할 수 있는 도구가 있습니다.
- Custom Metrics: 표준 지표 외에도 비즈니스 목표에 맞는 사용자 지정 지표를 정의할 수 있습니다.
Fairness와 Bias
- Bias 확인: 모델이 특정 그룹에 대해 편향되지 않았는지 확인해야 합니다.
- Fairness Metrics: 편향을 측정하는 여러 지표가 있으며, 이를 통해 모델의 공정성을 평가할 수 있습니다.
비용 효율성
- 모델 크기와 복잡성: 큰 모델은 높은 성능을 보이지만, 배포와 유지 관리 비용이 증가할 수 있습니다.
- Model Pruning: 모델 크기를 줄이기 위한 기법으로, 필요 없는 뉴런이나 레이어를 제거합니다.
- AutoML과 Hyperparameter Tuning: 자동화된 머신러닝 도구와 하이퍼파라미터 튜닝은 개발 시간을 단축시키고 최적의 모델을 찾는 데 도움을 줍니다.
- Grid Search vs Random Search: 하이퍼파라미터를 선택하는 두 가지 대표적인 방법입니다.
5. 도구와 리소스
LLM(Fine-Tuning)을 효과적으로 수행하기 위해서는 다양한 도구와 리소스가 필요합니다. 이 섹션에서는 이러한 도구와 리소스에 대해 깊이 있게 다룹니다.
1 오픈 소스 라이브러리
오픈 소스 라이브러리는 Fine-Tuning 작업의 기반이 됩니다. 이들은 논문에서 소개된 알고리즘을 실제 코드로 구현해 주는 중요한 역할을 합니다.
- Hugging Face Transformers: 이 라이브러리는 다양한 사전 훈련된 모델을 제공합니다. 특히, BERT, GPT-2 등의 모델을 쉽게 Fine-Tuning 할 수 있는 API를 제공합니다.
- TensorFlow Model Garden: TensorFlow를 사용하는 경우, 이 라이브러리는 다양한 모델과 그에 대한 Fine-Tuning 코드를 제공합니다.
- PyTorch Hub: PyTorch 기반의 모델을 찾고자 한다면, 이곳에서 다양한 모델을 찾을 수 있습니다.
2 클라우드 서비스
클라우드 서비스는 대규모 데이터와 고성능 하드웨어가 필요한 Fine-Tuning 작업을 용이하게 만듭니다.
- Google Colab: 무료로 GPU를 제공하며, Jupyter Notebook 형식의 환경을 제공합니다.
- AWS Sagemaker: 특히 대규모 모델을 다룰 때 유용하며, 자체적으로 모델 튜닝과 배포 기능을 제공합니다.
- Microsoft Azure ML: Microsoft의 클라우드 기반 ML 서비스로, 다양한 모델과 데이터셋을 쉽게 관리할 수 있습니다.
3 데이터셋
좋은 데이터셋은 모델의 성능을 크게 좌우합니다. 따라서, 고품질의 데이터셋을 선정하는 것은 매우 중요합니다.
- Common Crawl: 이 데이터셋은 다양한 언어와 주제를 포괄하고 있어, 다목적 Fine-Tuning에 유용합니다.
- SQuAD: 자연어 처리 분야에서 가장 유명한 질문 응답 데이터셋입니다. 이를 통해 모델의 질문 응답 능력을 향상할 수 있습니다.
- GLUE and SuperGLUE: 다양한 자연어 처리 작업을 위한 벤치마크 데이터셋입니다.
4 하드웨어
하드웨어는 모델 훈련 속도와 성능에 큰 영향을 미칩니다. 따라서, 적절한 하드웨어의 선택은 Fine-Tuning의 성공을 위해 중요합니다.
- NVIDIA GPUs: CUDA 지원으로 인해 대부분의 딥 러닝 작업에 사용됩니다.
- AMD GPUs: ROCm 지원을 통해 TensorFlow나 PyTorch에서 사용이 가능합니다.
- TPUs: Google에서 제공하는 TPU는 매우 높은 병렬 처리 능력을 가지고 있습니다.
5 최적화 도구
최적화 도구를 통해 모델 훈련 과정을 효율적으로 만들 수 있습니다.
- TensorBoard: 모델의 다양한 지표를 실시간으로 확인할 수 있습니다.
- Optuna: Bayesian optimization을 기반으로 하이퍼파라미터를 자동으로 튜닝합니다.
- Weights & Biases: 모델의 성능을 기록하고 분석할 수 있는 도구입니다.
6. Fine-Tuning vs. 다른 방법들
LLMs (Large Language Models)의 다양한 활용이 두드러지지만, 모든 애플리케이션에 이를 적용하는 것은 효율적이지 않을 수 있습니다. 이 글에서는 Fine-Tuning과 다른 학습 방법들에 대해 깊이 있게 다룰 예정입니다.
Fine-Tuning
Fine-Tuning은 기존에 훈련된 모델을 특정 작업에 최적화하기 위한 추가 학습을 의미합니다. 이 방법은 시간과 리소스를 크게 절약할 수 있습니다.
- 장점: 기존 지식을 활용, 빠른 학습 가능
- 단점: 오버피팅의 위험성
- 적용 사례: 챗봇, 검색 엔진, 번역 서비스
Zero-Shot Learning
Zero-Shot Learning은 본 적 없는 새로운 작업이나 데이터에 대해 모델이 어느 정도 성능을 발휘할 수 있게 하는 학습 방법입니다.
- 장점: 데이터가 부족한 상황에서도 유용
- 단점: 일반적으로 성능이 떨어짐
- 적용 사례: 이미지 분류, 언어 이해
Few-Shot Learning
Few-Shot Learning은 매우 적은 양의 레이블이 붙은 데이터로 모델을 훈련시키는 방법입니다.
- 장점: 적은 데이터로도 어느 정도 성능 향상
- 단점: 특정 작업에 대한 세부 조정이 어려움
- 적용 사례: 의료 이미지 분석, 텍스트 분류
Transfer Learning
Transfer Learning은 하나의 작업에서 훈련된 모델을 다른 작업에 적용하는 것입니다. Fine-Tuning은 이의 한 예입니다.
- 장점: 다양한 작업에 빠르게 적용 가능
- 단점: 소스 작업과 타깃 작업이 유사해야 효과적
- 적용 사례: 음성 인식, 자연어 처리
Key Comparisons
| Method | Data Requirement | Flexibility | Performance |
|---|---|---|---|
| Fine-Tuning | High | Medium | High |
| Zero-Shot Learning | Low | High | Low |
| Few-Shot Learning | Medium | Medium | Medium |
| Transfer Learning | Medium | High | High |
각 학습 방법은 자신의 특성과 적용 분야가 있으며, 이에 따라 선택해야 합니다. 프로젝트의 목표와 제약 조건을 고려하여 가장 적합한 방법을 선택하시기 바랍니다.
엔비디아 사례로 갈음
엔비디아의 GPU는 딥러닝 모델, 특히 Large Language Models (LLM)의 Fine-Tuning에 있어서 중요한 역할을 합니다. 이 글에서는 엔비디아 GPU를 활용한 Fine-Tuning의 효율성과 성능에 대해 알아보겠습니다.
GPU의 중요성
딥러닝 모델의 훈련과 Fine-Tuning은 계산량이 많은 작업입니다. 엔비디아의 GPU는 이러한 작업을 빠르고 효율적으로 수행할 수 있는 하드웨어입니다.
엔비디아의 특별한 기능
엔비디아는 CUDA라는 병렬 컴퓨팅 플랫폼과 API 모델을 제공합니다. 이를 통해 딥러닝 모델의 Fine-Tuning 과정이 더욱 빠르고 효율적으로 이루어집니다.
CUDA의 장점
- 빠른 데이터 전송 속도
- 효율적인 메모리 관리
- 높은 병렬 처리 능력
실제 성능 지표
엔비디아 GPU를 사용하면 CPU만을 사용할 때에 비해 Fine-Tuning 시간이 대폭 줄어듭니다. 이는 모델을 빠르게 개발하고 배포하는 데 큰 이점을 줍니다. 엔비디아의 GPU와 CUDA 기술은 LLM의 Fine-Tuning에 있어서 빠르고 효율적인 수행을 가능하게 합니다. 이를 통해 개발자와 연구자는 더욱 빠른 시간 안에 높은 성능의 모델을 구축할 수 있습니다.
LLM과 Fine-Tuning은 매우 다양한 분야에서 활용 가능하며, 이 블로그 포스팅을 통해 그 중요성과 활용 사례를 알아보았습니다. 여러 학습 방법과 비교 분석을 통해, Fine-Tuning이 어떤 상황에서 가장 효과적인지도 알아보았습니다. 이 정보가 독자 여러분께 유용한 지식을 제공하였기를 바랍니다. 오늘도 테크씬이었습니다!

'AI' 카테고리의 다른 글
| DT IT 개념 비교 : IT DT DX 차이점 (feat. 디지털리터러시) (1) | 2023.10.31 |
|---|---|
| 머신러닝 유사도 및 거리 총정리 : 코사인, 유클리디안, 자카드, 멘하탄 등 알고리즘 (1) | 2023.10.30 |
| RAG와 LLM 결합 : 자연어 처리의 새로운 지평(Retrieval-Augmented Generation) (0) | 2023.10.27 |
| 16주 데이터 사이언티스트 되기 : 커리큘럼 of 데이터 사이언스 (0) | 2023.08.24 |
| 분석 세계 : 데이터 사이언티스트 및 빅데이터 분석가 Deep-Dive (0) | 2023.07.04 |